
Neural Networks for Music Creation
by Kisko Apeles
Executive Summary
Ever since, it has been my dream to become a songwriter or an artist so I thought of creating music using neural networks. I used the humble LSTM architecture to predict note pitch, offsets, and duration of notes via separate models. The final models had acceptable final loss metrics and were able to generate music one could take inspiration from.
Since I was in high school, I wanted to make music and make people sing catchy lines. I wanted to make people feel.
Being a songwriter or an artist is the dream. So I thought, why don't I use neural networks to create new music.
Data and Methods
I have two originally composed demo songs that I can work with already and I wanted to try and create a song that is somewhere in between the two or a mix. The songs are available for listening here: https://soundcloud.com/kisko-apeles
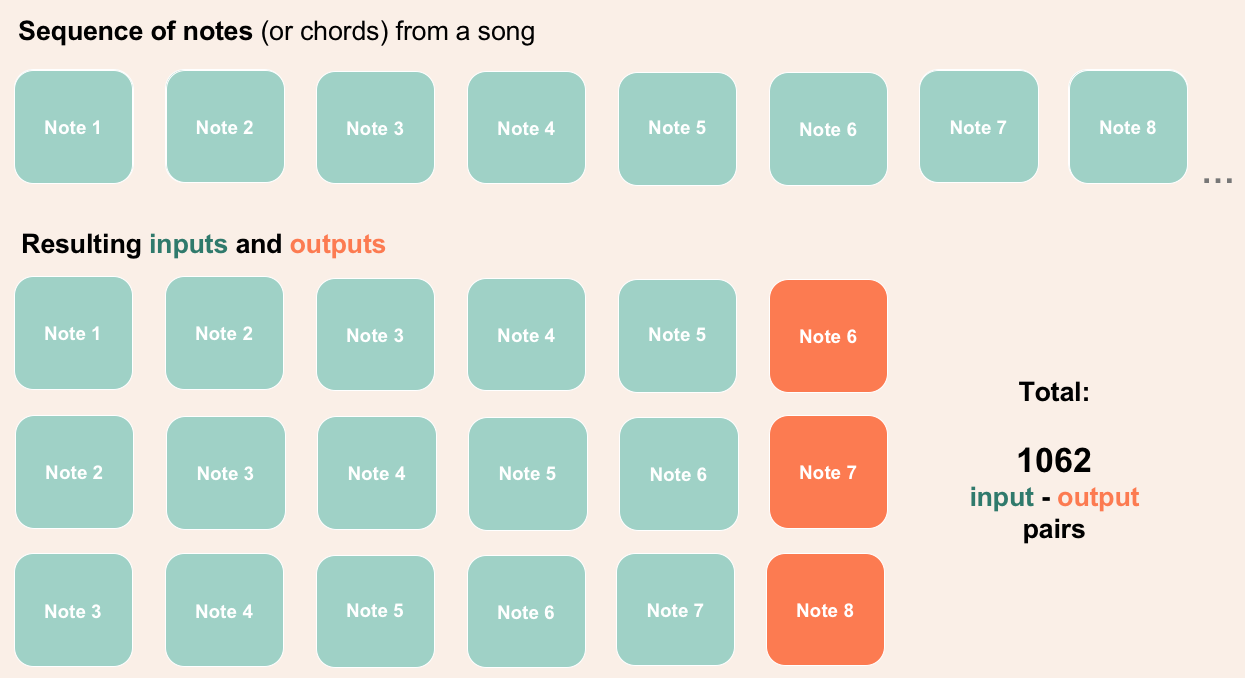
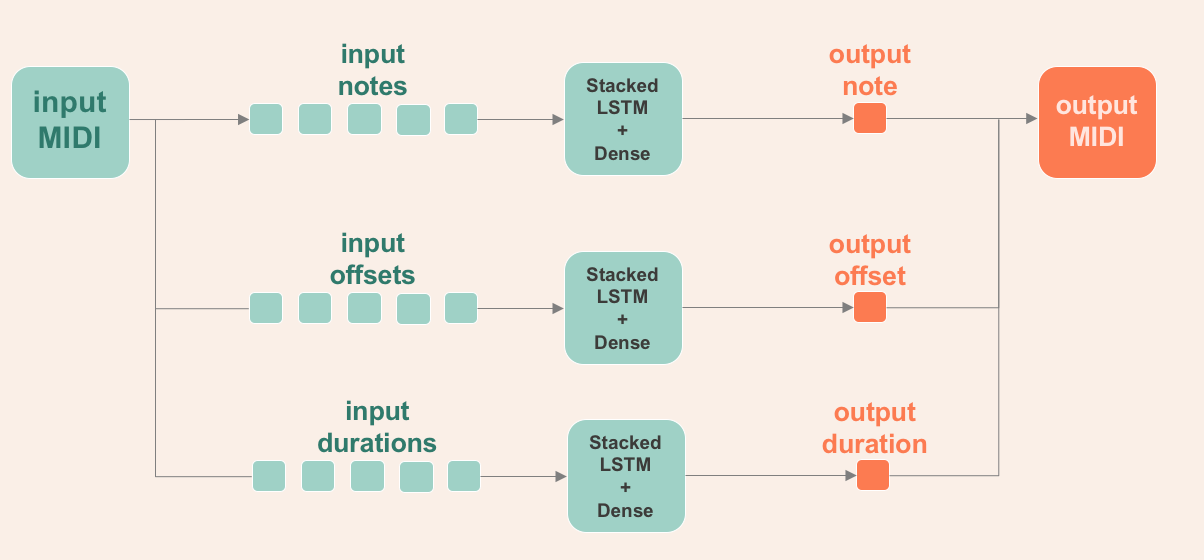
To accomplish my objective, I chopped up the songs in MIDI format to 5 notes each as the input and the next note as the output as shown in the diagram below. Five notes were chosen as input for the dataset to still have enough notes for learning the intro of the songs.
Now that I have my dataset, I proceeded with the following methodology:
- Exploratory Data Analysis
- Training, Fine tuning, and Model Evaluation
- MIDI Generation
Exploratory Data Analysis
I looked at the output note distribution of my dataset and I noticed that there are some notes that I prefer more than others.
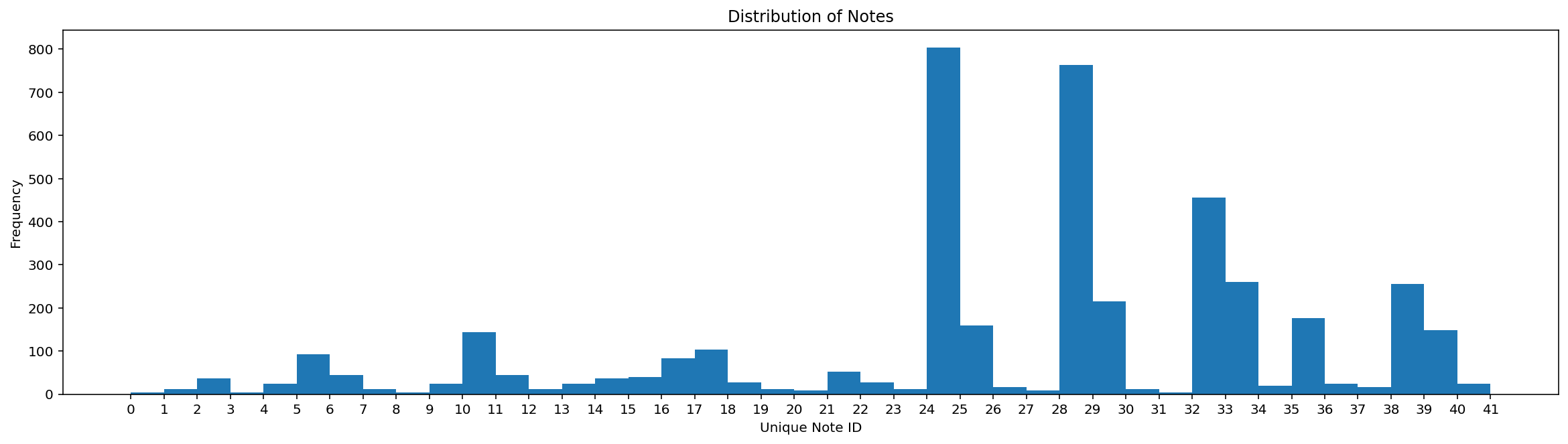
Given that, I realized I had to alleviate the impact of this bias and after looking at the documentation of model.fit() in Keras, I saw that there is a class_weight argument which can take class weights per class that will modify the loss function and force the model to exert effort in learning to predict notes that are less represented than others.
Training and Fine tuning
I used one of the model architectures for music creation shared in our LSTM notebook that was used in predicting the next songs. The LSTM used was a regular Stacked LSTM + Dense architecture but I saw an addition that is somewhat new to me, which is batch normalization. Upon searching what batch normalization mostly impacts, I learned that it helps a lot in speeding up training time by normalizing the inputs before activation functions.

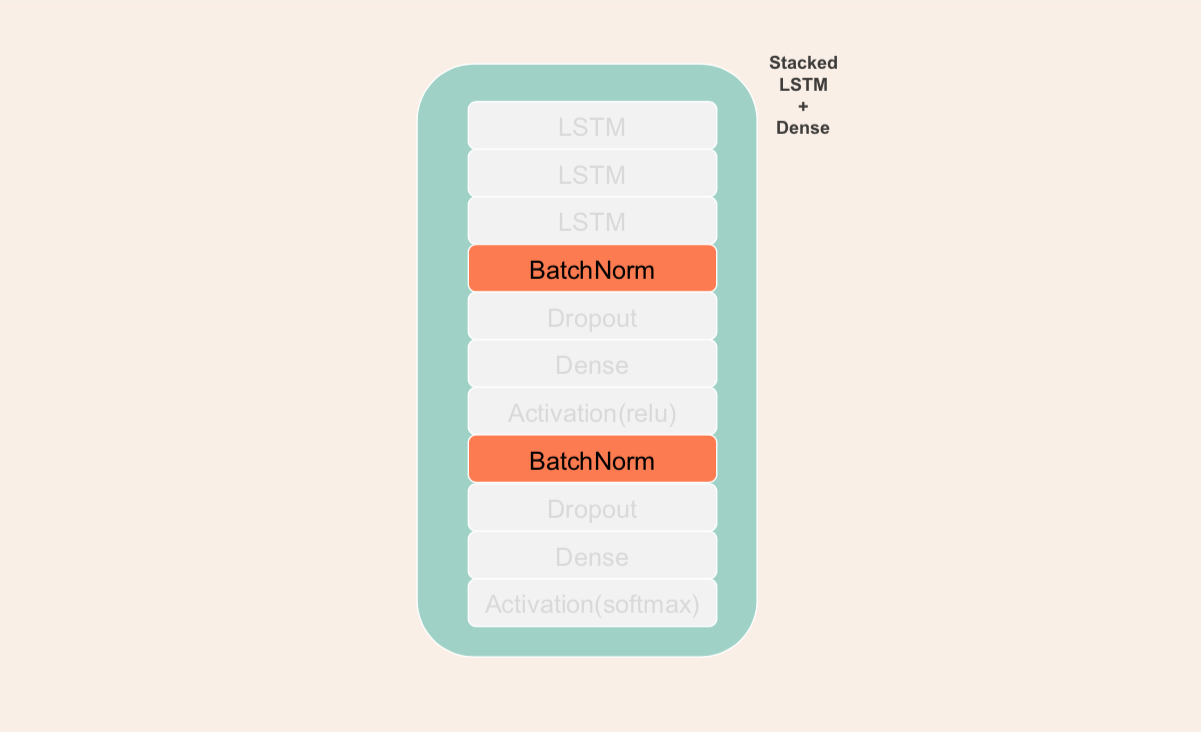
To add more flavor to the music generation, I added two LSTMs parallel to it to also predict offset, the distance between notes, and duration, how long the notes are played or sustained. I built them separately because I wanted to mix and match the offset timing of genres with notes profile of other genres later on if ever this architecture will be effective.
In the fitting of the model, I also added class weights since my dataset was unbalanced where some notes or chords were more represented than others.
In tuning the model, I played around with the following parameters:
- No of hidden nodes.
- No of dense layers.
- No of batch norm layers
- No of dropout layers
I stopped tuning when the output MIDI was almost acceptable to my ears.
Results and Discussion
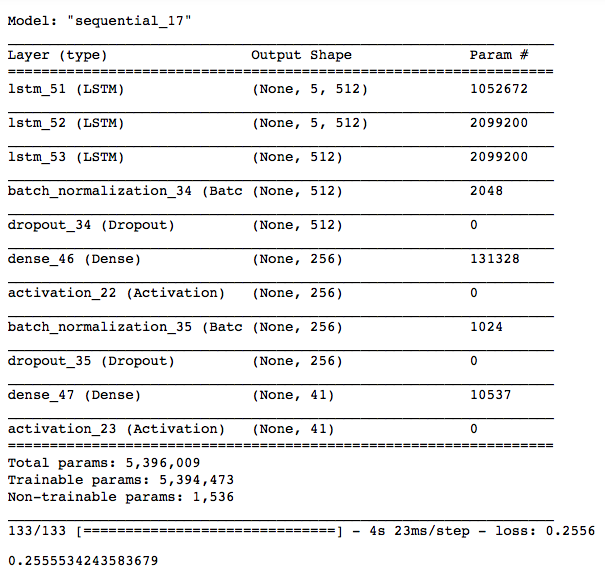
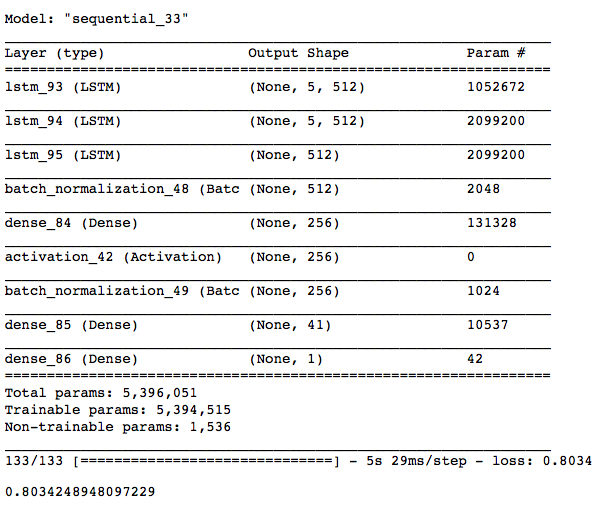
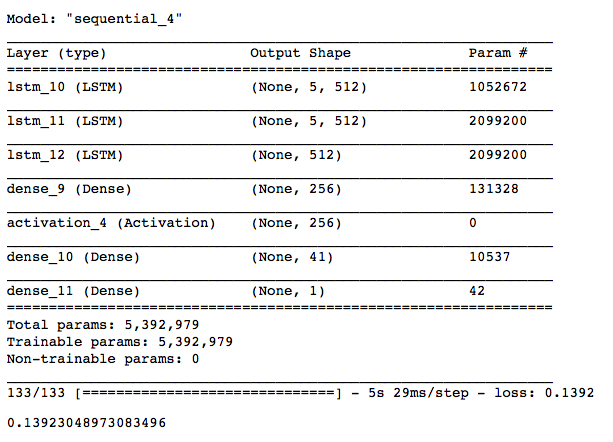
After tuning the three models and further adding training epochs, I have arrived at these final architectures. With the following evaluation metric results:
- 0.26 - Categorical Cross Entropy Loss - Notes Model
- 0.8 Quarter Notes - Mean Absolute Error - Duration Model
- 0.14 Quarter Notes - Mean Absolute Error - Offset Model
Notes Prediction Model
Duration Prediction Model
Offset Prediction Model
MIDI Generation
I used the models to generate a MIDI file (see included “output.midi”) and I was a bit off timing. It seemed that the LSTM architecture only learned how to predict the next note due to the model architecture but was not able to learn the structure of the song (i.e., intro-verse-chorus-verse-etc).
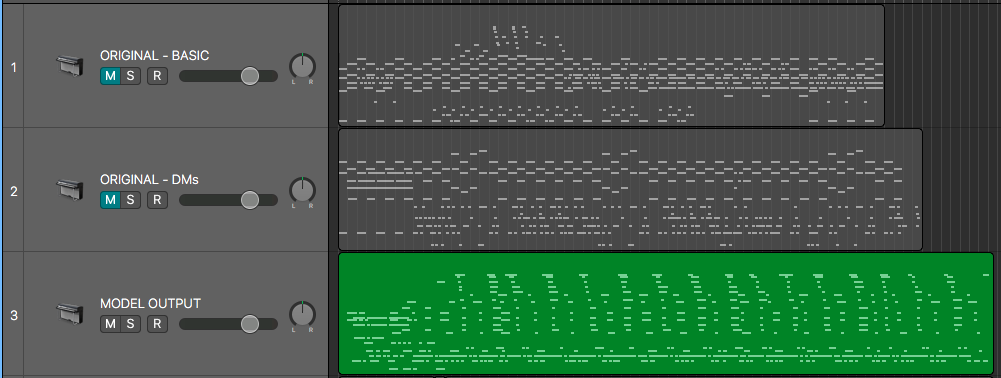
Here is the generated music using neural networks:
Conclusion and Recommendations
In conclusion, the LSTM architecture for song prediction was able to generate fairly accurate notes, offsets, and durations. However, it was not yet able to learn the structure of the song (i.e., intro-verse-chorus-verse-etc).
Further modifications can still be done to improve the results of the model. These improvements are the following:
- Increase the notes per input-output pair.
- Use other architectures like transformers or auto-encoders.
- Add more song inputs.
For now, its output can instead be used to generate music one could take inspiration from.
The following references have been very helpful in the execution of this project:
- Music Generation using LSTMs: https://towardsdatascience.com/how-to-generate-music-using-a-lstm-neural-network-in-keras-68786834d4c5
- Source code: https://github.com/Skuldur/Classical-Piano-Composer
- BatchNorm: https://www.youtube.com/watch?v=DtEq44FTPM4
- class_weight: https://datascience.stackexchange.com/questions/13490/how-to-set-class-weights-for-imbalanced-classes-in-keras